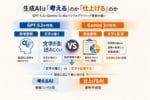
GPT-5.2とGemini3の画像作成で大きな違いが出るのはなぜか
「考える」のか「仕上げる」のか、生成AIの設計思想に決定的な違い
2025.12.25(木)


ここからは、JBpress Premium 限定です。
カンタン登録!続けて記事をお読みください。詳細はこちら
ここからは、JBpress Premium 限定です。
カンタン登録!続けて記事をお読みください。詳細はこちら










フォロー機能とは、指定した著者の新着記事の通知を受け取れる機能です。
フォローした著者の新着記事があるとヘッダー(ページ上部)のフォロー記事アイコンに赤丸で通知されます。![]()
フォローした著者の一覧はマイページで確認できます。![]()
※フォロー機能は無料会員と有料会員の方のみ使用可能な機能です。
記事ページのタイトル下にある「フォローする」アイコンをクリックするとその記事の著者をフォローできます。
フォロー中の著者を確認したい場合、ヘッダーのマイページアイコンからマイページを開くことで確認できます。
フォローを解除する際は、マイページのフォロー中の著者一覧から「フォロー中」アイコンをクリック、
または解除したい著者の記事を開き、タイトル下にある「フォロー中」アイコンをクリックすることで解除できます。






