「ビッグデータが富を生む」幻想を抱いていませんか?
リーマンショックと軌を一にして使われ始めた背景を知っておこう
2017.7.7(金)
ここからは、JBpress Premium 限定です。
カンタン登録!続けて記事をお読みください。詳細はこちら



あわせてお読みください
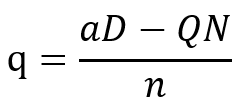

世界の中の日本 バックナンバー

地政学・経済安全保障から見て2026年には何が起きるのか?専門家が選定した10のクリティカル・トレンドを読み解く
菅原 淳一

政治にも実は企業経営にも不向きな生成AI、頼りすぎれば現場は大混乱
伊東 乾

なぜ古代日本では遷都が繰り返されたのに、平安京で終わったのか?古代日本の宮殿と遷都が映し出す権力と政治
関 瑶子

「ヒロシマのタブー」避け、硬直化し定型化した語りで「核兵器なき世界」を実現できるのか
宮崎 園子

2026年、重要性増す社会的情動スキルとステージマネジャー猪狩光弘の凄技
伊東 乾

AIのお試し期間は2025年で終了、2026年に顕在化する5つのトレンドとAIで稼ぐ企業・コストになる企業を分ける差
小林 啓倫
フォロー機能とは、指定した著者の新着記事の通知を受け取れる機能です。
フォローした著者の新着記事があるとヘッダー(ページ上部)のフォロー記事アイコンに赤丸で通知されます。![]()
フォローした著者の一覧はマイページで確認できます。![]()
※フォロー機能は無料会員と有料会員の方のみ使用可能な機能です。
設定方法
記事ページのタイトル下にある「フォローする」アイコンをクリックするとその記事の著者をフォローできます。
確認方法
フォロー中の著者を確認したい場合、ヘッダーのマイページアイコンからマイページを開くことで確認できます。
解除方法
フォローを解除する際は、マイページのフォロー中の著者一覧から「フォロー中」アイコンをクリック、
または解除したい著者の記事を開き、タイトル下にある「フォロー中」アイコンをクリックすることで解除できます。