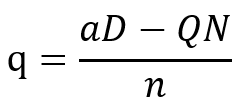ロシア・モスクワで、スウェーデンの日刊紙ダーゲンス・ニュヘテルのインタビューに応じるエドワード・スノーデン容疑者(2015年10月21日撮影)。(c)AFP/DAGENS NYHETER/LOTTA HARDELIN〔AFPBB News〕
2010年代に入ってからのAIブームには明確なきっかけがありました。
2012年6月26日に発表された、グーグルが資本投下して実施した「ディープラーニング」の大規模実験で、人間があらかじめ教えもしないのに、単に膨大なユーチューブ画像を視聴するだけで、ニューラルネットワークが「猫の顔」という概念を勝手に学習した・・・。
この「勝手に」というところが、決定的に重視されました。
それまでの情報処理は、あらかじめ人間が準備した概念があって、それに沿って記号操作を進めていくのが大前提でした。
文字情報はもとより、DNAの配列であれ、センサーがもたらす莫大な数字列であれ、何らかの意味で筆記的(scriptive)な情報に対して演算が施され、計算機は何らかの答えを出します。
これと対照的なのが人間の赤ん坊です。彼らは勝手に言葉を覚え、しゃべり出し、歩き出し、しなくてもいいことをたくさんしでかしてくれます。事前に定義した範囲内だけで行動してくれれば、育児はどれだけ楽でしょう?
善くも悪しくも、人間の脳は事前に定義した範疇を超えて勝手に概念を獲得してくれます。やや難しく言うなら記号表象の生成という言葉を使うこともあります。
逆にコンピューターは、事前に教えない概念を勝手に見出したりすることは、少なくともそれまではなかった。それができるようになったから、「今回のAIブームは本物だ!」ということで、国際投機熱を含めたブームが沸き起こっているわけですが。
その特徴をよく認識したうえで、ビッグデータその他の平行する技術トレンドを考えてみようというのが、今回のポイントです。
ビッグデータをどう見るか
第3次人工知能ブームで急速に発展するAIとともに考えるとき、私たちは「ビッグデータ」をどう見るべきか――。
ちょっと違う例から入ってみたいと思います。子供の頃、映画とテレビの違いがよく分からず、似たようなものだと思っていました。どちらも動画と音がある。でもテレビは自宅で無料で見られるのに、映画はお金を払って映画館に行かなければならない。
でも、夜などにテレビでもロードショー番組で映画がオンエアされるわけだから、「結局似たようなものだろう」程度に思って過ごしていました。
両者が全然違うと認識したのは、高校も卒業間近になって手にした評論家・蓮実重彦の書物を通じてのことでした。映画評論家でもある蓮実氏は、
「テレビを見るとバカになる」「家にテレビは置かない」
と、TVメディアに対してコテンパンで、最初はよくその意味が分かりませんでした。と言うより、特段の経験がなければ世の中の多くの人も昔の私と同じように意識しない方が普通だろうと思います。