ビッグデータを創薬開発に生かす
 東京医科歯科大学 名誉教授・特任教授
東京医科歯科大学 名誉教授・特任教授東北大学 東北メディカル・メガバンク機構
機構長特別補佐・特任教授
医療情報学国際Academy(FIAHSI)創立会員
田中 博 氏
「新薬の開発は年々時間とコストがかかるようになってきています。最近では、1000億円以上の開発費をかけても、市場に出る医薬品は1個以下になっています」と話すのは、東京医科歯科大学 名誉教授の田中博氏だ。
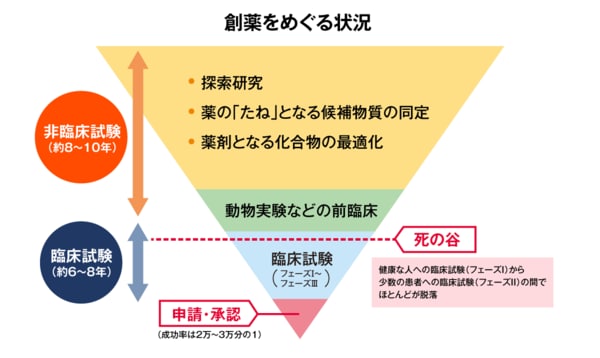
医薬品の開発のプロセスでは、ターゲット(標的)となる生体標的分子の分類をみつける探索研究に始まり、薬の「たね」となる候補物質の同定、薬剤となる化合物の最適化、さらには動物を使った非臨床試験、そして人間に適用する臨床試験(フェーズⅠ~フェーズⅢ)へと進んでいく。
だが、「成功率は2万~3万分の1といったところです。ほとんどがフェーズⅠとフェーズⅡの間で脱落してしまいます。そのためにここを『死の谷』と呼んでいます」と田中教授は語る。フェーズⅡに至るまで10年以上の期間を要することも珍しくない。「死の谷」を越え、開発の成功率を高めるためには、できるだけ早い段階で候補となる薬剤の有効性や毒性を予測することが必須となる。
「例えば、患者さんのiPS細胞を使って臨床予測を早期に実施するのも一つの方法です」患者から採取したiPS細胞には、まさに患者ごとの疾患特異性などの「情報」が乗っている。これを利用することで、早い段階での臨床予測が可能になるわけだ。
「人間の『製剤-疾患-生体系』のビッグデータを創薬開発の早期の段階から使う、という取り組みが今後ますます進んでくると考えられます」と田中教授は話す。
「ビッグデータ創薬」「AI創薬」が発展
データをもとにコンピュータを使って特定の標的に最適な化合物を見つける、というと、未来のテクノロジーのように感じるが、田中教授は「『計算創薬(in silico創薬)』という手法はかなり前からあり、実績もあります。これは分子の結合構造を中心に、分子構造解析、分子設計を行うものです」と話す。
具体的には、標的分子と薬剤の分子構造を根拠に、標的に結合する新薬候補の化合物を最適化する。まさに量子力学の世界だ。田中教授によればインフルエンザ薬の「タミフル」も、この計算創薬によって誕生したものだという。
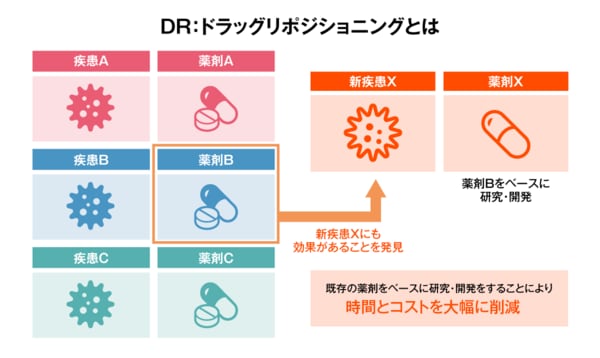
また、ドラッグ・リポジショニング(DR:薬剤適応拡大)においても、計算創薬は広く活用されているようだ。ドラッグ・リポジショニングとは、人での安全性と体内動態が十分にわかっている既存の薬から新しい薬理効果を発見し、その薬を別の疾患治療薬として開発することだ。すでに承認されている薬なので、開発の成功率が高く、時間とコストを大幅に削減できるという特長がある。
「『計算創薬』の新たな方向として、『生体プロファイル型創薬』があります。これは標的分子と薬剤が結合した後の、生体システムのゲノムワイドな反応・振る舞いに注目するものです。さらに、『生体プロファイル型創薬』は大きく、『ビッグデータ創薬』と『AI(人工知能)創薬』の2つに分けることができます」
薬の有効性、毒性・副作用が一目瞭然に
ビジネスの現場では「ビッグデータ」という言葉を聞く機会が増えているが、創薬においてもビッグデータ時代が到来しようとしている。
「次世代シーケンサー(遺伝子の配列を高速で解析できる装置)が普及するなど、バイオテクノロジーの発展によって膨大な生命情報が蓄積できるようになりました」と田中教授は話す。これらの生命情報ビッグデータを活用した創薬の取り組みも進みつつあるわけだが、「これらへのアプローチとして、非学習的アプローチの『ビッグデータ創薬』と、ディープ・ラーニング(深層学習)を活用した、学習的アプローチの『AI創薬』があるわけです」と田中教授は話す。
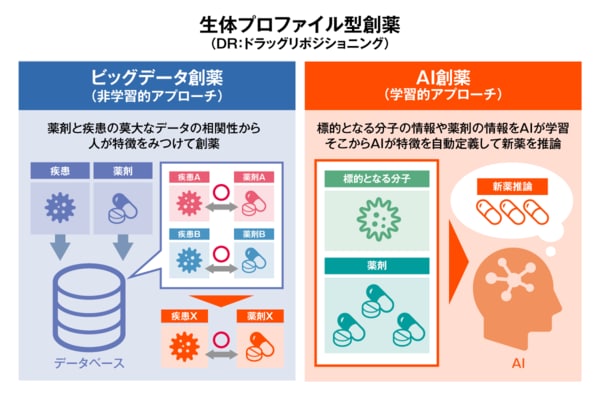
非学習的アプローチ(ビッグデータ創薬)の一つに、遺伝子発現プロファイルなどを比較することで、薬剤の有効性や毒性・副作用などを予測する方法がある。
「疾患特異的遺伝子発現プロファイルにはGEO(Gene Expression Omnibus)、薬剤特異的遺伝子発現プロファイルにはCMAP(Connectivity Map)などのプロファイルのビッグデータがあります。両者が負に相関(逆相関)すれば、薬剤の有効性が期待でき、正に相関すれば毒性・副作用が予測できます。両者の関係は相関図(マップ)として可視化することができるため、まさに一目瞭然で予測可能になります」
ほかにも非学習的アプローチ(ビッグデータ創薬)により、興味深い結果が示されたという。「疾患を遺伝子の発現パターンにより分類したところ、心筋梗塞とデュシャンヌ型筋ジストロフィーがきわめて近い位置に分類されました。一般的に、心筋梗塞なら循環器内科、循環器科、筋ジストロフィーなら脳神経内科と専門も分かれていたわけですが、臓器別の疾患分類では予想できない親近性が確認できました」
AIによる学習的アプローチが注目される
今注目されているのがディープ・ラーニング(深層学習)を活用した学習的アプローチによる「AI創薬」だ。
田中教授は次のように解説する。「非学習的アプローチは、膨大なプロファイルデータを比較して新しい答えを探す方法です。それに対して、学習的アプローチとは、これまでの有効な薬の属性を学習し、新たな薬を推論する方法なのですが、AI創薬に関する興味深い結果も出ています。2012年に開かれたデータサイエンスの競技会で、米メルク社が、15種類の生体の標的分子に対して、有効な数千~約1万に及ぶ化合物データから異なる構造活性相関のデータを学習させ、有効性未知の化合物の生物学的活性を予測するというコンテスト行いました。優勝したのは2人の大学院生のチームでしたが、驚いたことに、いずれも医薬品化学者ではなく情報科学系の専攻だったことです」。大手製薬会社の研究員が何年もかけて行うような研究・開発を、AIがわずかの期間で行えるということが実証されたわけだ。
「その後、各大学や研究機関でAI創薬の研究が進み、数万もの標的分子に対する数十万の化合物を対象とする研究でも有効性が予測できるようになりました」
AI創薬の研究が大きく前進していると言えるが、実用化に向けて課題があるとすればどのような点なのだろうか。「標的となる分子を決めることができれば、膨大な化合物データから有効なものを探し出すことができます。ただし、特定の疾病に対して、どの分子を標的にすべきかといったことは、世界でもまだ研究は途上といったところです」
日本の製薬会社が連携し「日本発」の新薬を
「海外のビッグファーマはこぞってAI創薬に取り組んでいます。AI創薬に特化したスタートアップ企業も数多く誕生しており、ビッグファーマとのコラボレーションも進んでいます」と田中教授は紹介する。
日本の製薬会社はこれらの動きに後れを取っていないのだろうか。
「日本の製薬会社ではまだ、AI創薬に本格的に取り組んでいるところは少ないようです。しかし、海外勢もまだスタートしたばかり。まだまだ追いつき追い越すことが可能です」
そのために鍵になるのはどのようなことだろうか。「大切なのはやはりデータです。ビッグデータの活用はデータの量が成否を大きく左右します。例えばアルツハイマーの治療薬は、高齢化社会を迎えている日本において高いニーズがありますが、比較できるデータの取得までに数十年かかることもあり、なかなか収集が難しいところです。そのあたりは課題ではありますが、日本の製薬業界が連携し、各社が保有するデータを共有するといった取り組みが実現すれば、海外のメガファーマにも先んじることができると考えています。『医療・創薬 データサイエンスコンソーシアム』などでは、データ共有などのプロジェクトも進めています。ぜひご参加いただき、AI創薬による『日本発』の新薬の開発を実現してほしいと願っています」と田中教授は結んだ。

<PR>