写真提供:ロイター/共同通信イメージズ
写真提供:ロイター/共同通信イメージズ
2025年初頭、世界中で話題となった生成AI「ディープシーク(DeepSeek)」。チャットGPTと遜色ない性能で、しかも無料で使えるとあって、わずか1カ月で1億ダウンロードを達成した。しかし、この中国発AIの真の革新性は、ユーザー自身がデータを管理できる「分散型AI」の概念を取り入れていることにある。そう遠くない未来に、「誰もが自分のAIを持ち、使いこなす時代」がやって来るかもしれない――そのとき、私たちはAIとどう向き合うべきなのか。ソフトバンクやアクセンチュアでAI エンジニアとして活躍してきた著者が、ディープシークの可能性と課題、そして生成AIの未来について記した『DeepSeek革命』(長野陸著/池田書店)から内容の一部を抜粋・再編集。
今回は、英語圏発のAIでは克服が難しいとされていた言語課題から、ディープシークの強みに迫る。
ディープシークはいかにして漢字特有の言語課題を克服するのか
 『DeepSeek革命』(池田書店)
『DeepSeek革命』(池田書店)
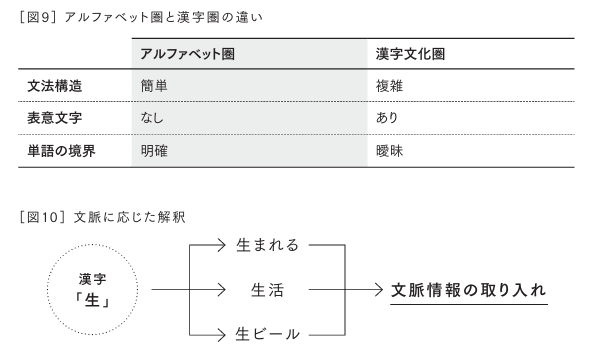
言語モデルが進化する中で、漢字文化圏の言語を適切に処理することは大きな技術的課題となっています。日本語や中国語など文字の形そのものが意味を表す「表意文字」を含む言語は、英語などのアルファベットや音素を基本とする言語とは構造が異なるため、モデルの訓練や推論の際に独自の難しさがあります。
これまでの言語モデルの多くは、アルファベット圏の言語に最適化されており、そのままの設計では漢字文化圏の言語に対応するには不十分でした。特に、単語の分割、多義的な解釈、文脈依存の処理、敬語の適用など、さまざまな技術的な壁が存在します。
日本語や中国語において、単語の境界を特定することは容易ではありません。
英語であれば、単語はスペースで区切られているため、比較的簡単に単語単位の意味を処理できます。しかし、日本語や中国語では文中に明確な単語の区切りが存在しないため、言語モデルが自動的に分割を行う必要があるのです。