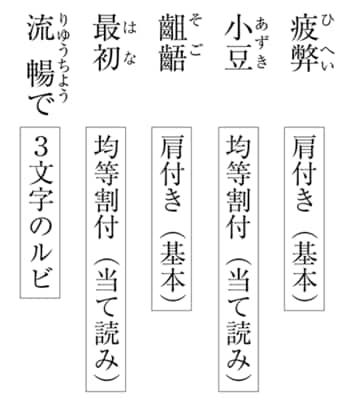
 図1 「京極ルビ基準」に基づくルビのサンプル
図1 「京極ルビ基準」に基づくルビのサンプル
ギャラリーページへ
一般にルビは中付きが多いようですが、京極ルールでは基本的に肩付き(漢字のアタマ揃え)を採用しました。なぜかというと、その漢字の本来の読み方ではない、当て読みと差別化するためですね(図1)。小豆は「小」で「あ」、「豆」で「ずき」とは読みませんよね。こういう場合は2文字の漢字に対して「あずき」を均等に振る。しかし、3文字の漢字に3文字の当て読みのルビが付くときは、中付きだと漢字1文字に1文字のルビが付くわけで、通常の場合と区別がつかなくなっちゃいます。
漢字2文字の単語の、上の漢字に3文字のルビがある場合、下の漢字に1文字かかってしまいます。ルビを漢字の上に出すのもイヤなので、この場合は漢字の間を半角空ける。これは活版の頃のスタイルに一部準拠してるんですが、この方がきれいです。ただしその場合隣の行と文字の位置が半角ずれてしまう。ルビを計算に入れると難易度がうんと上がります。
行頭や行末に特定の文字が来ないように
版面を作る場合、禁則事項というものがあります。行頭や行末に特定の文字や記号が来ないようにすることです。句読点が行頭に来ることは基本的に避けるので、そのような場合、「ぶら下がり」「追い込み」「追い出し」という方法で対処します(図2)。