

 mundissima / Shutterstock.com
mundissima / Shutterstock.com
2025年初頭、世界中で話題となった生成AI「ディープシーク(DeepSeek)」。チャットGPTと遜色ない性能で、しかも無料で使えるとあって、わずか1カ月で1億ダウンロードを達成した。しかし、この中国発AIの真の革新性は、ユーザー自身がデータを管理できる「分散型AI」の概念を取り入れていることにある。そう遠くない未来に、「誰もが自分のAIを持ち、使いこなす時代」がやって来るかもしれない――そのとき、私たちはAIとどう向き合うべきなのか。
ソフトバンクやアクセンチュアでAI エンジニアとして活躍してきた著者が、ディープシークの可能性と課題、そして生成AIの未来について記した『DeepSeek革命 オープンソースAIが世界を変える』(長野陸著/池田書店)から内容の一部を抜粋・再編集。今回は、従来のクラウド型AIにはない、「分散型AI」という発想を取り入れたディープシークならではの強みと、それを支える技術基盤に迫る。
ディープシークは何を目指すのか巨大IT依存からの脱却
 『DeepSeek革命』(池田書店)
『DeepSeek革命』(池田書店)
ディープシークの開発ミッションは、「分散型AIを通じて、誰もが自由に利用できる高性能なAI基盤を提供すること」でした。
アメリカのクラウド型AIは、数千億のパラメータを持つ巨大モデルの運用に適している一方で、一部の世界的に影響力のある巨大なIT企業が計算リソースを独占し、中小企業や個人開発者にとって利用しづらい状況が生まれていました。
さらに、AIモデルのトレーニングに使用されるデータが特定の企業や国に集中することで、データの公平性や主権に関する懸念も浮上しています。
ディープシークは、従来のクローズドなAIモデルとは異なり、開かれた開発環境を整えることで、より多くの研究者やエンジニアが参加できるプラットフォームを目指しています。これにより、技術革新のスピードを加速させると同時に、特定の企業や国に依存しないAIの発展を促進しています。
特に中国や欧州では、データローカライゼーション(データを国内で管理する規制)が進んでおり、国や企業ごとに独自のAI基盤を構築する必要性が高まっています。
ディープシークは、このような状況を打破し、より分散的で持続可能なAIモデルの提供を目指して開発されました。
また、ディープシークはオープンソースによる透明性向上や外部監査可能な仕組みを整備し、これらのリスクへの対応を進めています。このミッションの実現には、技術面だけでなく、オープンソース戦略やエコシステム(※)の構築も欠かせません。
(※)複数組織が連携し価値を生み出す協力関係や環境のこと。
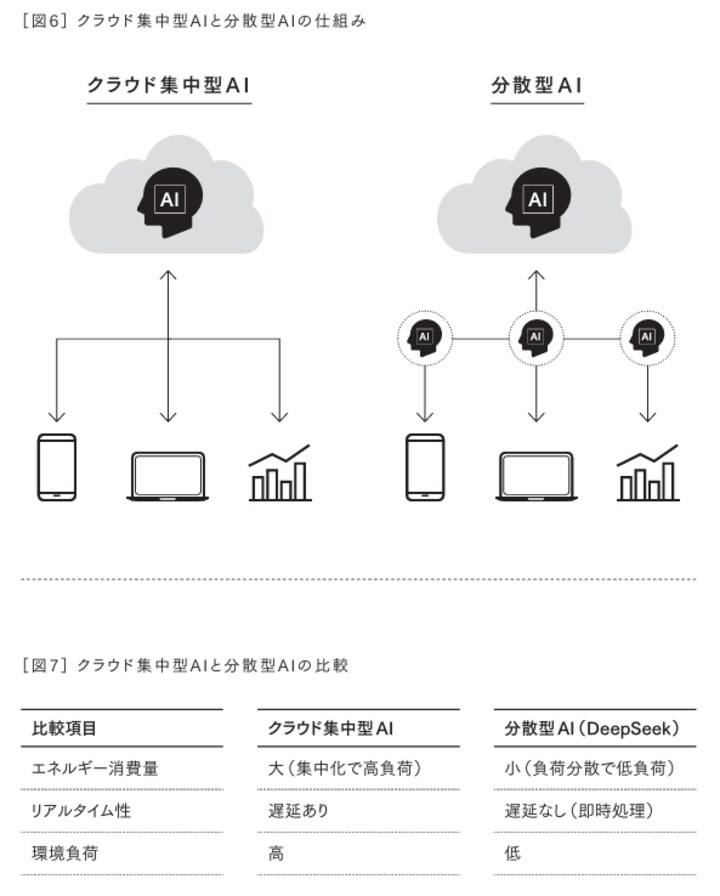
ディープシークは技術的な側面だけでなく、エネルギー効率や環境負荷の低減も重視しています。クラウド集中型AIは、大規模なデータセンターを運用するために膨大な電力を消費しますが、ディープシークは分散型のアプローチを採用することで、エネルギーをより効率的に活用し、持続可能なAIの開発を実現しようとしています。
特に、エッジデバイスやローカルサーバーでのAI推論を最適化することで、電力コストを抑えながら高度なAI機能を提供することを目指しています。
このように、ディープシークは単なる技術的な進化ではなく、AIの開発・運用のあり方そのものを変革しようとしているのです。
「大規模な事前学習」と「推論の最適化」という強み
ディープシークには大きな技術的な強みが二つあります。大規模な事前学習(pretraining)によって高度な知識を獲得する能力と、推論最適化(inference optimization)による効率的なAIモ二ル運用です。
大規模な事前学習
近年の大規模言語モデルは、より多くのデータと計算リソースを用いた学習を通じて、高度な自然言語処理能力を獲得しています。
ディープシークも同様に、膨大なデータセットを活用した事前学習を行い、多様な言語や分野に対応できる汎用的な知識を獲得しています。高品質なテキストデータの選別と学習効率を高める手法を組み合わせ、学習の質と速度の両立を実現している点が特徴です。
また、ディープシークは分散型AIアーキテクチャに適した事前学習技術を取り入れており、単一の巨大なデータセンターではなく、複数のコンピュータや装置(ノード)に分散された計算環境での学習を実現しています。
従来のクラウド集中型AIでは、トレーニングに使用されるデータが一部の企業や国に集中することが問題視されていましたが、ディープシークの分散型アプローチでは、ローカルな計算リソースを活用しながらも高精度な学習を行うことが可能です。この仕組みにより、データ主権の保護やエネルギー効率の向上といった利点が生まれています。
推論の最適化
一方で、AIモデルが実際に利用される際の「推論(すでに学習済みのAIモデルを使って、新しいデータに対して予測や判断を行うプロセス)」の最適化も重要な課題です。
特に、大規模モデルによる推論は計算コストが高いため、リアルタイムでの応答速度や、低消費電力での運用が求められます。ディープシークでは、推論時の計算負荷を軽減する技術を導入し、より高速かつ省エネルギーでの運用を可能にしています。
たとえば、量子化(AIモデルの計算負荷を減らし、軽量化するために数値表現の精度を下げる技術)や蒸留(大規模なAIモデルから、小規模なAIモデルへ知識を圧縮する技術)といった技術を活用し、モデルのサイズを最適化しながらも、精度の低下を最小限に抑える工夫がなされているのです。
また、ディープシークの推論最適化には、エッジデバイスやオンプレミス環境での利用を想定した調整も含まれています。従来のクラウド型AIは、大規模なサーバー環境を前提とした運用が多かったのに対し、ディープシークはより分散型の運用を可能にすることで、小規模な環境でも効率的に活用できるAIモデルを提供しています。
これにより、企業や研究機関が独自の環境でAIを導入しやすくなり、AI技術の民主化が進むことが期待されています。
<著者フォロー機能のご案内>
●無料会員に登録すれば、本記事の下部にある著者プロフィール欄から著者をフォローできます。
●フォローした著者の記事は、マイページから簡単に確認できるようになります。
