

第1回 データイノベーションフォーラム
特別講演2「データに基づく仮説検証サイクルを実現するためのデータサイエンス機能のポイント」
開催日:2024年3月21日(木)
主催:JBpress/Japan Innovation Review
DXの実現において鍵となるデータの活用。データを存分に活用するためには、どのような機能が必要なのか。塩野義製薬 データサイエンス部長・北西由武氏は「データに基づく仮説検証サイクルを高速かつ高品質に回すためには、データエンジニアリングが不可欠」と語ります。その上で、ビジネスにおけるデータ活用の課題から、塩野義製薬におけるデータサイエンス組織の設計、人材育成まで幅広く解説。
データの多様化と量、リアルタイム性が大きく進化していく中、ますます重要性を増していくデータ活用の基本について、多くの知見が得られる講演です。
【TOPICS】
- ビジネスデータサイエンスの基本プロセス
- データドリブン型ビジネスを行うために
- データ活用を進める上での問題点とは
- データの分類と仮説検証サイクル
- データ活用組織をつくる3つのポイント
- データベースと解析システムの設計コンセプト
- データエンジニアリングにおける可視化と解析
- 人材育成コンセプトとデータドリブン人材強化の取り組み
- データ活用の推進に向けて
データサイエンスとデータエンジニアリングの重要性
北西由武氏(以下、北西氏) 塩野義製薬 データサイエンス部長の北西です。これから、「データに基づく仮説検証サイクルを実現するためのデータサイエンス機能のポイント」というテーマでお話しします。
まず自己紹介から始め、データサイエンスとデータエンジニアリングの重要性、データ活用機能のポイントとしての組織の設計等についてお話しし、最後にまとめをします。
早速ですが、自己紹介です。私は2003年に入社し、まず臨床統計を担う解析センターという部署でファーストキャリアをスタートしました。これは薬の有効性や安全性を確認するための試験設計や、解析方法をどのようにするかというような、製薬会社にとっては非常に重要な役割を担う部署です。
その後、2020年にコーポレート全体のデータサイエンスを強化するためにデータサイエンス室が設置され、その室長に就任しました。さらに、今回の話の肝となるデータエンジニアリングの機能も含めたデータサイエンス部が2021年に創設され、現在はその責任者を務めています。
では、データサイエンスとデータエンジニアリングの重要性についてお話しします。
経産省のデジタルガバナンス・コード2.0では、DXは「企業がビジネス環境の激しい変化に対応し、データとデジタル技術を活用して、顧客や社会のニーズを基に、製品やサービス、ビジネスモデルを変革するとともに、業務そのものや、組織、プロセス、企業文化・風土を変革し、競争上の優位性を確立すること」とあります。
ここで一つポイントとなるのが、「データとデジタル技術」というように、「データ」が定義されているところです。では、データを活用するにはどのような機能が必要なのか。データを活用する機能として、ビジネスデータサイエンスの基本プロセスを紹介します。
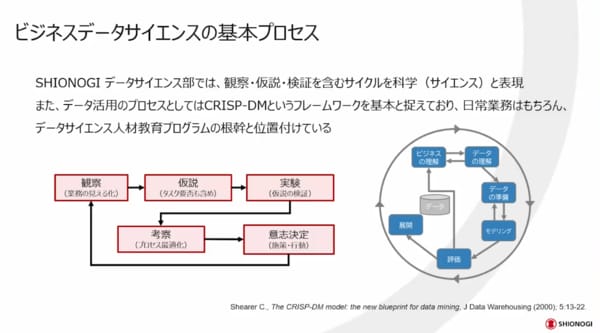
「データサイエンス」なので、サイエンスの基本、例えば観察し仮説を立てて実験し、考察して意思決定をするというサイクルを、いかに高速にかつ高品質に回すかが重要になります。例えばデータで見ても、リアルワールドデータを観察することにより仮説を立てるというプロセスも考えられます。
データ活用のプロセスでもう一つ大事なのが、CRISP-DMというフレームワークです。ビジネスの理解からデータの理解、データの準備、モデリング、評価、展開と続きますが、「データの理解」が最も肝になると思っています。
これを、さらに図式化したものが下の図です。

仮説と検証のサイクルを繰り返し回すのですが、そのためにはデータのリテラシーの強化が全社員に必要だと考えています。なぜかと言うと、業務部門とデータサイエンスのコア人材とが議論をして、仮説検証をデータサイエンスのところで回していく上で、データサイエンスのコア人材だけが突っ走ってしまってはいけないからです。そこは、業務部門の人と綿密に議論をして仮説検証サイクルを回していく必要があります。
コミュニケーションを取るためには、全社員のデータリテラシー、業務部門のデータリテラシーの強化も非常に重要なポイントです。それができるように、データ活用組織を設計しなければなりません。
その上に、システムがあります。これは、統合データベースと統合解析環境です。データをいかに高品質かつリアルタイムに集約してくるか、そしてそれをいかに効率的かつ高度に解析できるかがポイントになります。今回、当社の中でこの2つを新たに更新、構築してリリースできたことが大きく進捗したトピックです。
データがどのような形か、さらに解析結果としてどのようなアウトプットがされたか、ということを、全てデータカタログの中に記録し、それらの検索性を向上させ、運用しています。そうすることで、過去にどのような仮説検証のサイクルが回っていたのかを確認できます。以前誰かがやったことをそのまま引き継いで、また新たな仮説検証ができるよう、システムを構築しました。その上で、ビジネス戦略・戦術の立案・実行を行います。このような一連の流れを積み上げていくことが、ビジネスにおけるデータを活用実現し、加速する一つのポイントになると思っています。
ビジネスでデータ活用を進める上での課題
北西氏 一般的に、データサイエンスはどのように認識されているでしょうか。
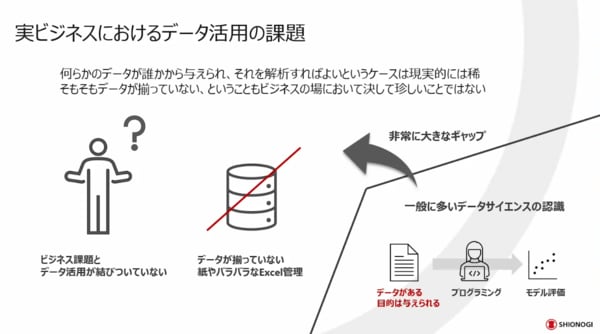
よく言われるのは、「ここにデータがあるから、解析して知見やインサイトを与えてほしい」というようなことです。しかし、実際は、それではなかなかうまくいかないケースが多いと思います。
それは、ビジネス課題とデータ活用が結びついていない場合、もしくはデータがあると言っても、その品質が極めて悪い場合があるからです。また、データが全くそろっていない、一部が紙で入力から始めないといけない、いつ誰がどこで入力したデータなのか分からない、というようなケースも多々あります。
そのような質の悪いデータを解析しても、質の良い解析結果は出てきません。まずデータがどのように集められたのか、それが業務部門内でどのように管理されていたのかなどを入念にヒアリングし、ビジネス課題もしっかりと目線合わせをした上で解析を進めていくことが非常に重要なポイントです。
この図では、データ活用を進める上での問題点を整理しています。
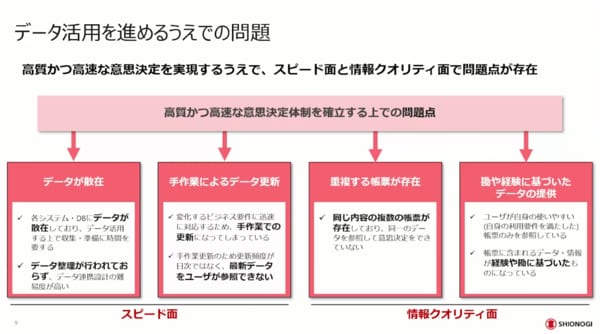
データが散在している、手作業によるデータの更新で非常に時間がかかる、重複する帳票があちこちに存在していて違う結果が複数存在するという場合もあります。また、勘や経験に基づいていて、非常に恣意(しい)性の高いデータを使っているケースもあります。このように、スピード面と情報のクオリティー面で問題点が存在するケースが多々あるかと思います。
これを防ぐためには、データの流れと検討の流れを双方向にきちんと確認した上で、データの流れを確立していくことが重要です。
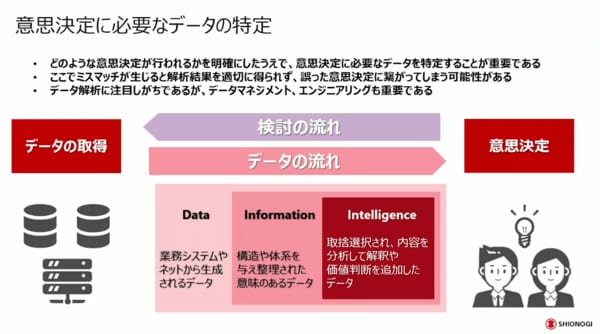
データの分類と活用のポイント
北西氏 今の話でお気付きかもしれませんが、データの管理は非常に大事です。私の自己紹介でも述べたとおり、データマネジメントやデータエンジニアリングでデータを活用するには、データを管理する機能が絶対に必要だと考えています。そこで、そのような機能をうまく連携させながら組織設計をしています。
具体的に、データ活用組織の設計と機能について説明します。この図は、データの大分類と仮説検証サイクルについてまとめたものです。
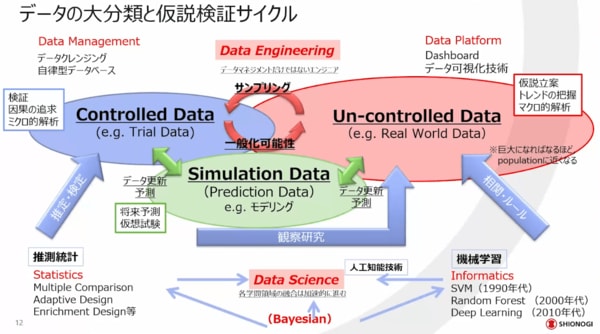
大きく分けて、データにはコントロールされて取られたデータと、コントロールされずに集積しているデータがあります。
例えば、薬の効果を確認する研究で、実薬なのかプラセボなのかを分からないようにした上で比較することがあります。このケースは比較のために管理されたデータということができます。
一方で、リアルワールドデータがあります。これもさまざまですが、例えば比較をしない目的で集積されたデータを比較目的で使おうとすると、なかなかうまくいかないことがあります。だから、どのような特徴があるデータなのかを理解した上で、検証に使うためのデータなのか、仮説立案に使うデータなのか、というような認識をすることが大事になってきます。
最近は、それぞれシミュレーションでデータを生成しながら、さらにデータをリッチにしていくようなケースもあります。例えば推測統計のような検証で使う方法と、機械学習で相関ルールを見つけて仮説を立案するようなケースなど、いろいろなものをうまくミックスさせながら実際に仮説検証サイクルを回していくのがデータサイエンスであると認識しています。 また、データのマネジメントとデータプラットフォームをうまく管理することは、データエンジニアリングとして非常に重要なポイントになってきています。
データ活用組織としての3つのポイント
北西氏 続いて、データ活用組織としてのポイントです。
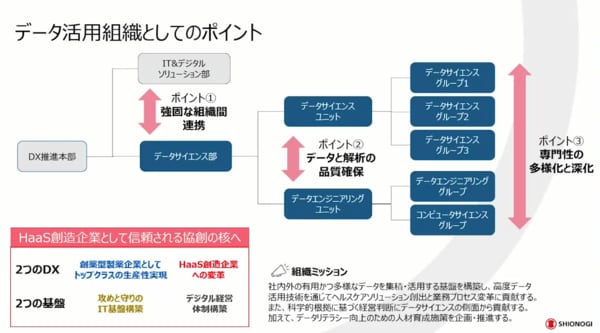
弊社の場合、DX推進本部というDXを推進する組織体があります。その中に、データサイエンス部とIT&デジタルソリューション部があります。1つ目のポイントとして、ITの組織とデータ活用組織が隣に位置していることが非常に大事です。
なぜかと言うと、例えばシステムを導入すると、そこからは確実に多くのデータが創出されます。2つの組織が連携していれば、「どのような項目をどのような管理の下で取っていくか」というようなことを初期段階から一緒に考えることができます。導入、リリース後に「このようなデータが出てきたので何か活用して結果をください」と言われることもありますが、先ほどお話ししたとおり、データを取るところからしっかりとマネジメントをしていかないと見たい結果も得られないことが多いです。そのため、この2つの組織の連携が非常に大事なのです。
2つ目のポイントは、データサイエンスユニットとデータエンジニアリングユニットという組織が並んでいることです。これも同じような話なのですが、データ活用をするにはやはりデータの質がポイントです。しっかりと品質を確保しながらデータを蓄積していくデータエンジニアリングユニットが、データ活用を行うデータサイエンスユニットと一緒になって二人三脚でデータ活用を進めていくことが、大きなポイントと言えます。
3つ目のポイントは、専門性の多様化と深化です。当社には、データサイエンスグループ1・2・3と、データエンジニアリンググループ、コンピューターサイエンスグループという組織があります。この体制の目的は、それぞれが専門性を深めつつも多様化することです。
例えば、データサイエンスグループ1には、リアルワールドデータの活用が得意なメンバーが比較的多く集まっています。他にも、例えば営業の解析や人事の解析など経営の解析に長(た)けたグループ、画像や動画、波形、音声などの解析に長けたグループというように、それぞれ特色があります。そして、いろいろな専門性を持ったメンバーが横断的にチームを組み、進めているところが大きなポイントだと考えています。
データベースと解析システムの設計コンセプト
北西氏 次に、データベースと解析システムの設計コンセプトです。
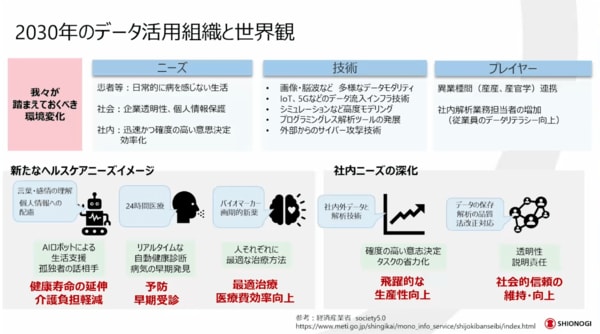
2030年のデータ活用組織と世界観は一体どのようになっているのかを考えると、今とは非常に大きく変わっていると思います。データの多様化と量、リアルタイム性などは、大きく進化しているでしょう。世間のニーズや技術、プレーヤーも大きく変化していると思います。ヘルスケアのニーズイメージも大きく変わり、社内ニーズもより複雑・多様化し、深くなっていると考えます。そのような時に、データは非常に大事なポイントになると思います。
現在はというと、当社内では研究から開発、生産、情報提供、流通・販売、安全性調査・報告というようなバリューチェーンがあります。データサイエンス部は研究の段階からいろいろな支援をしており、販売や情報提供においてもデータを活用して何かできないかとコミットしています。一方で、経営の観点から経理・財務、人事、ESG、広報などの部門でもデータは日々蓄積されているので、そのようなものをうまく活用しながら経営を推進していきたいと考えています。
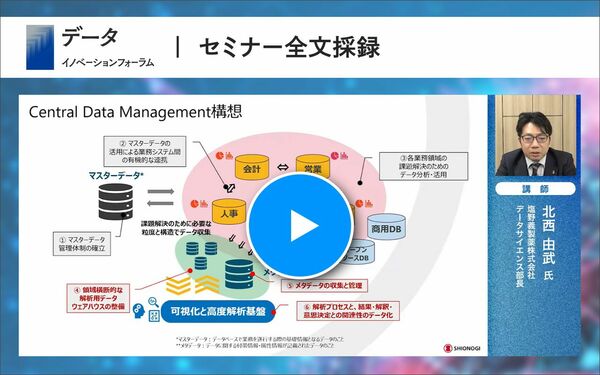
現在、弊社では「セントラルデータマネジメント構想」を推し進めています。
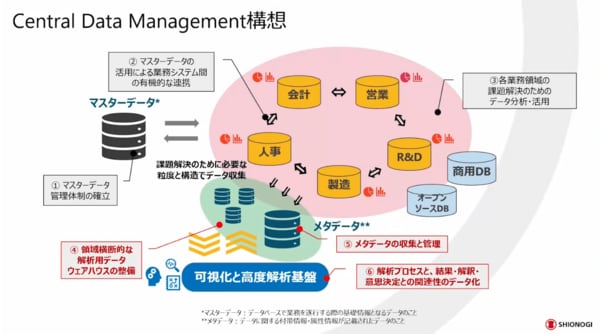
マスターデータ、メタデータの収集・管理も非常に大事ではありますが、最も大きなポイントは、解析プロセスと結果・解釈・意思決定との関連性のデータ化です。いつ、誰が、どこで、どのような目的でデータを使い、どのような解析をしたのか。目的を決めるところからきちんと記録として残すことをコンセプトにしています。
「そういえばAさんがあの時に解析していた」というような記憶をたどっていくのではなく、どのような活用事例があったのかデータカタログを検索して、その人のインサイトを得ながら、当時の資産もうまく使えることを目指しています。「どのような意思決定に使ったのか」という透明性を担保することにより、意思決定をする立場の人から見ても「この時にこのようなデータや解析結果を基に判断したのだろう」ということをたどれるようにしています。これが非常に透明性につながります。
今回、AWSのオンデマンド環境にPython、RならびにSnowflake、SAS Viya、可視化環境としてSpotfireなど、データベース環境と解析環境さらに可視化の環境を近くに配置し、データの連携が非常にうまくいくように社内のシステムを構成しリリースしました。
続いて、データエンジニアリングの可視化と解析についてです。

データエンジニアリングが大事であることは、お伝えしました。どこにどのようなデータがあるかを管理するデータライブラリアンやデータソムリエなども非常にキーとなる役割だと思いますし、データのライフサイクルマネジメントも管理していくべきだろうと考えています。何より、「このようなデータがあるとこのような活用ができるだろう」という予見性も、データエンジニアは兼ね備えてほしいところです。
例えば、上の図の下側に示しているような売り上げのシミュレーションや感染症の現在の状況を予測するには、「どのようなデータが必要か」という予見が必要です。また、ビジネスパーソンである弊社社員をどのような形で行動変容するかについても、データを活用できると思っています。
人材育成のコンセプトとさまざまな取り組み
北西氏 人材の育成コンセプトについてです。
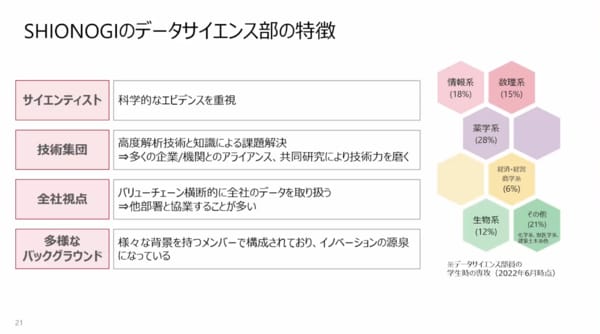
データサイエンス部に所属している人は、情報系か数理出身の人だろうとよく言われるのですが、実はそうではありません。3分の1ぐらいはそのような情報系、数理系の専攻だった人たちですが、残りは薬学系や、最近では経営の解析もしているのでそのような専門のバックグラウンドを持つメンバーもいます。
ここにはデータとしては示していませんが、いろいろな組織の職種からデータサイエンティストとして転向してくれた人たちもいます。もちろん、データエンジニアも同様です。だから、多様性を確保した中で仕事ができています。
業務部門への教育も大事です。人材育成については、階層ごとに違ったアプローチで教育をしています。
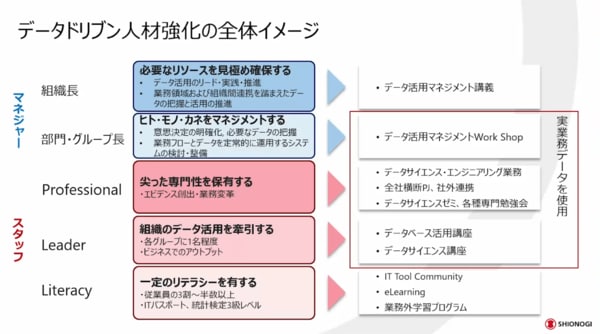
例えばマネジャー層では、ヒト・モノ・カネ・情報をどのような形でデータに基づいてマネジメントするかも非常に大事です。従来は、勘と経験、度胸だけでマネジメントしていた部分もあったと思います。勘、経験、度胸も大事ですが、納得感をもってマネジメントできるようにするためには、やはりデータの力は使うべきだろうと考えています。
「どのようなことがデータでできるのか」を認識し、「データ活用を進めてみないか」というように各組織でもデータ活用を推進してもらうためには、組織長への教育が大事だと考えています。
プロフェッショナルの人材ももちろん大事ですし、業務部門のリテラシーを上げてコミュニケーションを円滑に進めるために、階層ごとに多種多様なコンテンツを用意して教育をしています。
このような教育コンテンツを内製することも、一つのこだわりです。データサイエンス部員が教育コンテンツを作成し、実際に講師やメンターとして教育研修に携わっています。「教えることは教わること」で、教えることによって自分の理解も深まるという一面もあるので非常に大事にしているポイントです。
そのような活動を通じてデータサイエンス部が保有する技術として、道具と知識の例をこの図に示しています。
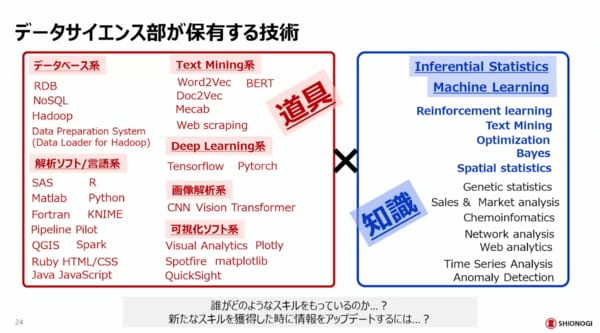
この図は5~6年前ぐらいに作ったもので、少しアップデートはしていますがほぼ当時のものです。このような形で、誰がどのような分野に強いのかをしっかりと把握しながら進めてきています。
また、このような情報を透明化し、社内で公開しています。「誰がどの分野に強い」というような情報共有は、従来は会話の中で行われていました。それを、検索してスムーズに知ることができるよう、タレントマネジメントシステムを内製しています。その人がどのようなタスクにアサインされたのか、どのようなコミットの仕方をしているかという情報も連携させて、うまく運用しています。そうすることで、コア人材の育成も加速できるのではないかと考えています。
一方で、データサイエンス部という名称どおり「サイエンス」にこだわり、社外発信も盛んに行っています。われわれは40~50名の組織ですが、学会や社外の発表・公演などを年間20件以上行っています。できれば1人年間1回程度は外で発表してきてほしいと考えています。また、論文をきちんと書くことが論理的思考やサイエンスを深める意味では大事な活動なので、論文投稿も積極的に行ってほしいと思っています。そして、このような技術をしっかりと知財化したいと思っており、少なくとも年間1~2件は取っていきたいと考えています。
最後に、本日のまとめです。
データエンジニアリングという言葉は、まだあまり聞きなれないかもしれませんが、今後非常に重要になってくるデータエンジニアとデータサイエンティストという職種の融合が、データ活用の推進に必須であると考えています。
目的に応じたデータを計画的かつ高品質に収集して蓄積していけるよう、可能な限り努めるべきだと考えています。また、業務部門との連携は必須であり、そのコミュニケーションを円滑に進めていくためには、業務部門側のリテラシー向上も重要であると考えています。
データ活用の専門性は、多様化と進化が進んできています。これらをしっかりデータ化して可視化し、モニタリングを行うことによって、コア人材の育成、さらには個人と組織も成長していけるように進めていくべきだと考えています。
私からのお話は以上です。ご清聴ありがとうございました。
